Elementary symmetric polynomial
In mathematics, specifically in commutative algebra, the elementary symmetric polynomials are one type of basic building block for symmetric polynomials, in the sense that any symmetric polynomial P can be expressed as a polynomial in elementary symmetric polynomials: P can be given by an expression involving only additions and multiplication of constants and elementary symmetric polynomials. There is one elementary symmetric polynomial of degree d in n variables for any d ≤ n, and it is formed by adding together all distinct products of d distinct variables.
Contents |
Definition
The elementary symmetric polynomials in  variables X1, …, Xn, written ek(X1, …, Xn) for k = 0, 1, ..., n, can be defined as
variables X1, …, Xn, written ek(X1, …, Xn) for k = 0, 1, ..., n, can be defined as
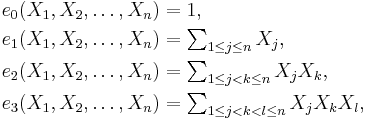
and so forth, down to
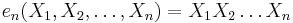
(sometimes the notation σk is used instead of ek). In general, for k ≥ 0 we define
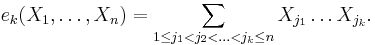
Thus, for each positive integer 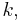 less than or equal to , there exists exactly one elementary symmetric polynomial of degree
less than or equal to , there exists exactly one elementary symmetric polynomial of degree  in variables. To form the one which has degree , we form all products of -tuples of the variables and add up these terms.
in variables. To form the one which has degree , we form all products of -tuples of the variables and add up these terms.
The fact that 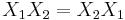 and so forth is the defining feature of commutative algebra. That is, the polynomial ring formed by taking all linear combinations of products of the elementary symmetric polynomials is a commutative ring.
and so forth is the defining feature of commutative algebra. That is, the polynomial ring formed by taking all linear combinations of products of the elementary symmetric polynomials is a commutative ring.
Examples
The following lists the n elementary symmetric polynomials for the first four positive values of n. (In every case, e0 = 1 is also one of the polynomials.)
For n = 1:
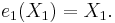
For n = 2:
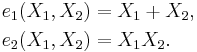
For n = 3:
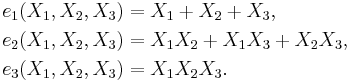
For n = 4:
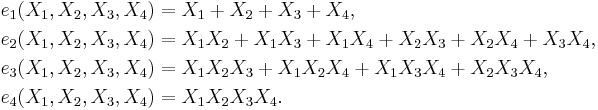
Properties
The elementary symmetric polynomials appear when we expand a linear factorization of a monic polynomial: we have the identity
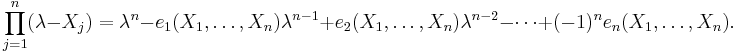
That is, when we substitute numerical values for the variables 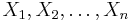 , we obtain the monic univariate polynomial (with variable λ) whose roots are the values substituted for and whose coefficients are the elementary symmetric polynomials.
, we obtain the monic univariate polynomial (with variable λ) whose roots are the values substituted for and whose coefficients are the elementary symmetric polynomials.
The characteristic polynomial of a linear operator is an example of this. The roots are the eigenvalues of the operator. When we substitute these eigenvalues into the elementary symmetric polynomials, we obtain the coefficients of the characteristic polynomial, which are numerical invariants of the operator. This fact is useful in linear algebra and its applications and generalizations, like tensor algebra and disciplines which extensively employ tensor fields, such as differential geometry.
The set of elementary symmetric polynomials in variables generates the ring of symmetric polynomials in variables. More specifically, the ring of symmetric polynomials with integer coefficients equals the integral polynomial ring ![\mathbb Z[e_1(X_1,\ldots,X_n),\ldots,e_n(X_1,\ldots,X_n)].](/2012-wikipedia_en_all_nopic_01_2012/I/0db81c210c44b68ad2d74e93c9f76d9f.png) (See below for a more general statement and proof.) This fact is one of the foundations of invariant theory. For other systems of symmetric polynomials with a similar property see power sum symmetric polynomials and complete homogeneous symmetric polynomials.
(See below for a more general statement and proof.) This fact is one of the foundations of invariant theory. For other systems of symmetric polynomials with a similar property see power sum symmetric polynomials and complete homogeneous symmetric polynomials.
The fundamental theorem of symmetric polynomials
For any commutative ring A denote the ring of symmetric polynomials in the variables  with coefficients in A by
with coefficients in A by ![A[X_1,\ldots,X_n]^{S_n}](/2012-wikipedia_en_all_nopic_01_2012/I/9d32401fa2e71683c610088ec6cd77b5.png) .
.
- is a polynomial ring in the n elementary symmetric polynomials
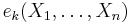 for k = 1, ..., n.
for k = 1, ..., n.
(Note that 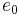 is not among these polynomials; since
is not among these polynomials; since 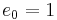 , it cannot be member of any set of algebraically independent elements.)
, it cannot be member of any set of algebraically independent elements.)
This means that every symmetric polynomial ![P(X_1,\ldots, X_n) \in
A[X_1,\ldots,X_n]^{S_n}](/2012-wikipedia_en_all_nopic_01_2012/I/ecfdc3f88039fa44cfdda641c8192c90.png) has a unique representation
has a unique representation

for some polynomial ![Q \in A[Y_1,\ldots,Y_n]](/2012-wikipedia_en_all_nopic_01_2012/I/72f4a4473f8d5ab85a50c36e61f88c5d.png) . Another way of saying the same thing is that is isomorphic to the polynomial ring
. Another way of saying the same thing is that is isomorphic to the polynomial ring ![A[Y_1,\ldots,Y_n]](/2012-wikipedia_en_all_nopic_01_2012/I/05afca5912c53948d0cfffc18141236c.png) through an isomorphism that sends
through an isomorphism that sends 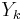 to for
to for 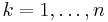 .
.
Proof sketch
The theorem may be proved for symmetric homogeneous polynomials by a double mathematical induction with respect to the number of variables n and, for fixed n, with respect to the degree of the homogeneous polynomial. The general case then follows by splitting an arbitrary symmetric polynomial into its homogeneous components (which are again symmetric).
In the case n = 1 the result is obvious because every polynomial in one variable is automatically symmetric.
Assume now that the theorem has been proved for all polynomials for 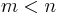 variables and all symmetric polynomials in n variables with degree < d. Every homogeneous symmetric polynomial P in can be decomposed as a sum of homogeneous symmetric polynomials
variables and all symmetric polynomials in n variables with degree < d. Every homogeneous symmetric polynomial P in can be decomposed as a sum of homogeneous symmetric polynomials
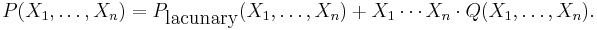
Here the "lacunary part" 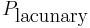 is defined as the sum of all monomials in P which contain only a proper subset of the n variables X1, ..., Xn, i.e., where at least one variable Xj is missing.
is defined as the sum of all monomials in P which contain only a proper subset of the n variables X1, ..., Xn, i.e., where at least one variable Xj is missing.
Because P is symmetric, the lacunary part is determined by its terms containing only the variables X1, ..., Xn−1, i.e., which do not contain Xn. These are precisely the terms that survive the operation of setting Xn to 0, so their sum equals 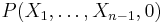 , which is a symmetric polynomial in the variables X1, ..., Xn−1 that we shall denote by
, which is a symmetric polynomial in the variables X1, ..., Xn−1 that we shall denote by 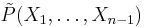 . By the inductive assumption, this polynomial can be written as
. By the inductive assumption, this polynomial can be written as
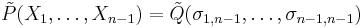
for some 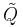 . Here the doubly indexed
. Here the doubly indexed 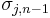 denote the elementary symmetric polynomials in n−1 variables.
denote the elementary symmetric polynomials in n−1 variables.
Consider now the polynomial
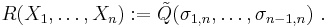
Then 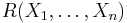 is a symmetric polynomial in X1, ..., Xn, of the same degree as , which satisfies
is a symmetric polynomial in X1, ..., Xn, of the same degree as , which satisfies
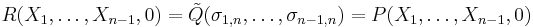
(the first equality holds because setting Xn to 0 in 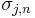 gives , for all
gives , for all 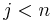 ), in other words, the lacunary part of R coincides with that of the original polynomial P. Therefore the difference P−R has no lacunary part, and is therefore divisible by the product
), in other words, the lacunary part of R coincides with that of the original polynomial P. Therefore the difference P−R has no lacunary part, and is therefore divisible by the product  of all variables, which equals the elementary symmetric polynomial
of all variables, which equals the elementary symmetric polynomial 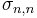 . Then writing
. Then writing 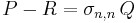 , the quotient Q is a homogeneous symmetric polynomial of degree less than d (in fact degree at most d − n) which by the inductive assumption can be expressed as a polynomial in the elementary symmetric functions. Combining the representations for P−R and R one finds a polynomial representation for P.
, the quotient Q is a homogeneous symmetric polynomial of degree less than d (in fact degree at most d − n) which by the inductive assumption can be expressed as a polynomial in the elementary symmetric functions. Combining the representations for P−R and R one finds a polynomial representation for P.
The uniqueness of the representation can be proved inductively in a similar way. (It is equivalent to the fact that the n polynomials  are algebraically independent over the ring A.) The fact that the polynomial representation is unique implies that is isomorphic to .
are algebraically independent over the ring A.) The fact that the polynomial representation is unique implies that is isomorphic to .
An alternative proof
The following proof is also inductive, but does not involve other polynomials than those symmetric in X1,...,Xn, and also leads to a fairly direct procedure to effectively write a symmetric polynomial as a polynomial in the elementary symmetric ones. Assume the symmetric polynomial to be homogenous of degree d; different homogeneous components can be decomposed separately. Order the monomials in the variables Xi lexicographically, where the individual variables are ordered X1>…>Xn, in other words the dominant term of a polynomial is one with the highest occurring power of X1, and among those the one with the highest power of X2, etc. Furthermore parametrize all products of elementary symmetric polynomials that have degree d (they are in fact homogeneous) as follows by partitions of d. Order the individual elementary symmetric polynomials ei(X1,…,Xn) in the product so that those with larger indices i come first, then build for each such factor a column of i boxes, and arrange those columns from left to right to form a Young diagram containing d boxes in all. The shape of this diagram is a partition of d, and each partition λ of d arises for exactly one product of elementary symmetric polynomials, which we shall denote by eλt (X1,…,Xn) (the "t" is present only because traditionally this product is associated to the transpose partition of λ). The essential ingredient of the proof is the following simple property, which uses multi-index notation for monomials in the variables Xi.
Lemma. The leading term of eλt (X1,…,Xn) is Xλ.
- Proof. To get the leading term of the product one must select the leading term in each factor ei(X1,…,Xn), which is clearly X1X2…Xi, and multiply these together. To count the occurrences of the individual variables in the resulting monomial, fill the column of the Young diagram corresponding to the factor concerned with the numbers 1…,i of the variables, then all boxes in the first row contain 1, those in the second row 2, and so forth, which means the leading term is Xλ (its coefficient is 1 because there is only one choice that leads to this monomial).
Now one proves by induction on the leading monomial in lexicographic order, that any nonzero homogenous symmetric polynomial P of degree d can be written as polynomial in the elementary symmetric polynomials. Since P is symmetric, its leading monomial has weakly decreasing exponents, so it is some Xλ with λ a partition of d. Let the coefficient of this term be c, then P − ceλt (X1,…,Xn) is either zero or a symmetric polynomial with a strictly smaller leading monomial. Writing this difference inductively as a polynomial in the elementary symmetric polynomials, and adding back ceλt (X1,…,Xn) to it, one obtains the sought for polynomial expression for P.
The fact that this expression is unique, or equivalently that all the products (monomials) eλt (X1,…,Xn) of elementary symmetric polynomials are linearly independent, is also easily proved. The lemma shows that all these products have different leading monomials, and this suffices: if a nontrivial linear combination of the eλt (X1,…,Xn) were zero, one focusses on the contribution in the linear combination with nonzero coefficient and with (as polynomial in the variables Xi) the largest leading monomial; the leading term of this contribution cannot be cancelled by any other contribution of the linear combination, which gives a contradiction.
A Self-Contained Algorithmic Proof
The following proof of the existence (not of the uniqueness) of Q is the same as the above, but rewritten in elementary terms and with slightly different choice of lexicographic order.
The symmetric polynomial 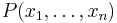 is a sum of monomials of the form
is a sum of monomials of the form  , where the
, where the 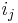 are nonnegative integers and
are nonnegative integers and 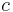 is a scalar (i. e., an element of our ring A). We define a partial order on the monomials by specifying that
is a scalar (i. e., an element of our ring A). We define a partial order on the monomials by specifying that
if 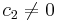 and there is some
and there is some 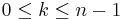 such that
such that 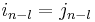 for
for 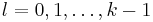 but
but 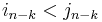 . For instance
. For instance 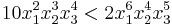 and
and 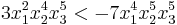 . (You have probably realized that the coefficients
. (You have probably realized that the coefficients 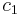 and
and 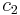 don't have any relevance in whether
don't have any relevance in whether 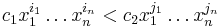 or not, as long as they are nonzero. It is the exponents that matter.) In words, starting in the nth position in both monomials, go back until the two exponents are not equal. The monomial with the larger exponent in that position is the larger monomial. This is called a lexicographic order on the monomials.
or not, as long as they are nonzero. It is the exponents that matter.) In words, starting in the nth position in both monomials, go back until the two exponents are not equal. The monomial with the larger exponent in that position is the larger monomial. This is called a lexicographic order on the monomials.
We reduce P into elementary symmetric polynomials by successively subtracting from P a product of elementary symmetric polynomials eliminating the largest monomial according to this order without introducing any larger monomials. This way, in each step, the largest monomial becomes smaller and smaller until it becomes zero, and we are done: the sum of the subtracted-off polynomials is the desired expression of P as a polynomial function of elementary polynomials.
Here is how each step of this algorithm works: Suppose is the largest monomial in P. Then we must have 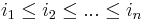 , since otherwise this monomial could not be the largest one of P (in fact, due to P being symmetric, the polynomial P must also have the monomial
, since otherwise this monomial could not be the largest one of P (in fact, due to P being symmetric, the polynomial P must also have the monomial  where
where 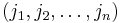 is the sequence
is the sequence 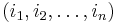 sorted in increasing order; but this monomial is larger than the monomial unless we have ). Thus, we can define a symmetric polynomial R by
sorted in increasing order; but this monomial is larger than the monomial unless we have ). Thus, we can define a symmetric polynomial R by
where 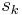 is the kth elementary symmetric polynomial in the n variables
is the kth elementary symmetric polynomial in the n variables  . Clearly R is a polynomial in the elementary symmetric polynomials. Now we claim that the largest monomial of R is . To prove this, we notice that the largest monomial of
. Clearly R is a polynomial in the elementary symmetric polynomials. Now we claim that the largest monomial of R is . To prove this, we notice that the largest monomial of 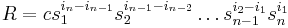 is clearly equal to
is clearly equal to
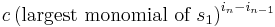
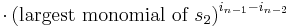

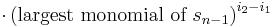
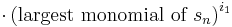
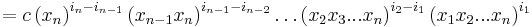
(since the largest monomial of 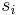 is
is 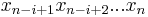 for every i).
for every i).
In this monomial, the variable 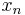 occurs with exponent
occurs with exponent 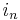 (since it occurs with exponent
(since it occurs with exponent 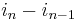 in the first term,
in the first term, 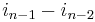 in the second term, and so on, down to
in the second term, and so on, down to 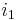 times in the final term), the variable
times in the final term), the variable 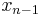 occurs with exponent
occurs with exponent 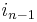 (since it occurs with exponent in the second term,
(since it occurs with exponent in the second term, 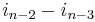 in the third term, and so on, down to times in the final term), and so on for the remaining variables. Hence, this monomial must be . Thus we have shown that the largest monomial of R is . Therefore, subtracting R from P eliminates the monomial , and all monomials of P-R are smaller than the one just eliminated. Thus, we have found a polynomial R, which is a polynomial in the symmetric polynomials, such that subtracting R from P leaves us with a new symmetric polynomial P-R whose largest monomial is smaller than that of P. We can now continue the process until nothing remains in P.
in the third term, and so on, down to times in the final term), and so on for the remaining variables. Hence, this monomial must be . Thus we have shown that the largest monomial of R is . Therefore, subtracting R from P eliminates the monomial , and all monomials of P-R are smaller than the one just eliminated. Thus, we have found a polynomial R, which is a polynomial in the symmetric polynomials, such that subtracting R from P leaves us with a new symmetric polynomial P-R whose largest monomial is smaller than that of P. We can now continue the process until nothing remains in P.
Here is an example of the above algorithm. Suppose 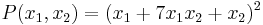 . Expanding this into monomials, we get
. Expanding this into monomials, we get
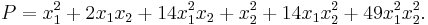
The largest monomial is 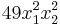 , so we subtract off
, so we subtract off 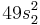 , getting
, getting
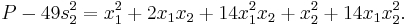
Now the largest monomial is 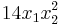 , so we subtract off
, so we subtract off 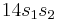 , getting
, getting
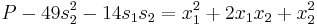
Now the largest monomial is 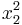 , so we subtract off
, so we subtract off 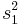 , getting
, getting
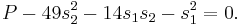
This gives
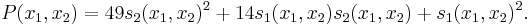
See also
References
- Macdonald, I.G. (1995), Symmetric Functions and Hall Polynomials, second ed. Oxford: Clarendon Press. ISBN 0-19-850450-0 (paperback, 1998).
- Richard P. Stanley (1999), Enumerative Combinatorics, Vol. 2. Camridge: Cambridge University Press. ISBN 0-521-56069-1